
RAG, CAG & Fine-tuning, on-prem AI implementations
The idea is simple: not every company wants to use AI “as is” out of the box—they need to adapt it with their own data, language, and context, while keeping everything secure and private.
There are currently 3 main ways to “customize” AI so it fits a company’s needs.
- CAG: ideal for speeding up repeated answers.
- RAG: perfect for consulting your company’s information in real time across thousands of documents.
- Fine-tuning: the AI learns to work exactly the way your company needs.
CAG (Cache-Augmented Generation)
Imagine you’re chatting with a friend in a café for hours about different topics. When you circle back to the first topic, they might not remember it clearly. This memory about the conversation in AI is known as the CONTEXT of the conversation and has an impact on the CAG.
With CAG, the most common or frequent answers are stored in a cache (a kind of fast memory, like RAM). Next time someone asks the same thing, the AI replies much faster and without “thinking” as much. But every AI has a context window that limits how much of the conversation history can be kept. If that window gets full, it naturally drops the oldest parts and keeps the newest—something to keep in mind no matter how large the context is.
Even so, CAG lets us save resources, cost, and time, ensures more consistent answers, and is very useful for frequently repeated questions. Examples: How do I create a new client? How do I register a client in my ERP? What’s the sales director’s phone number?
These questions are often repeated by new hires in the sales team. Instead of dedicating a person to train each new hire, you save resources, cost, and time.
How do you implement CAG in a local/on-prem AI?
In an on-prem AI model, whatever model you choose will have a CONTEXT—that’s the AI’s capacity to cache information. For example, in the image below:
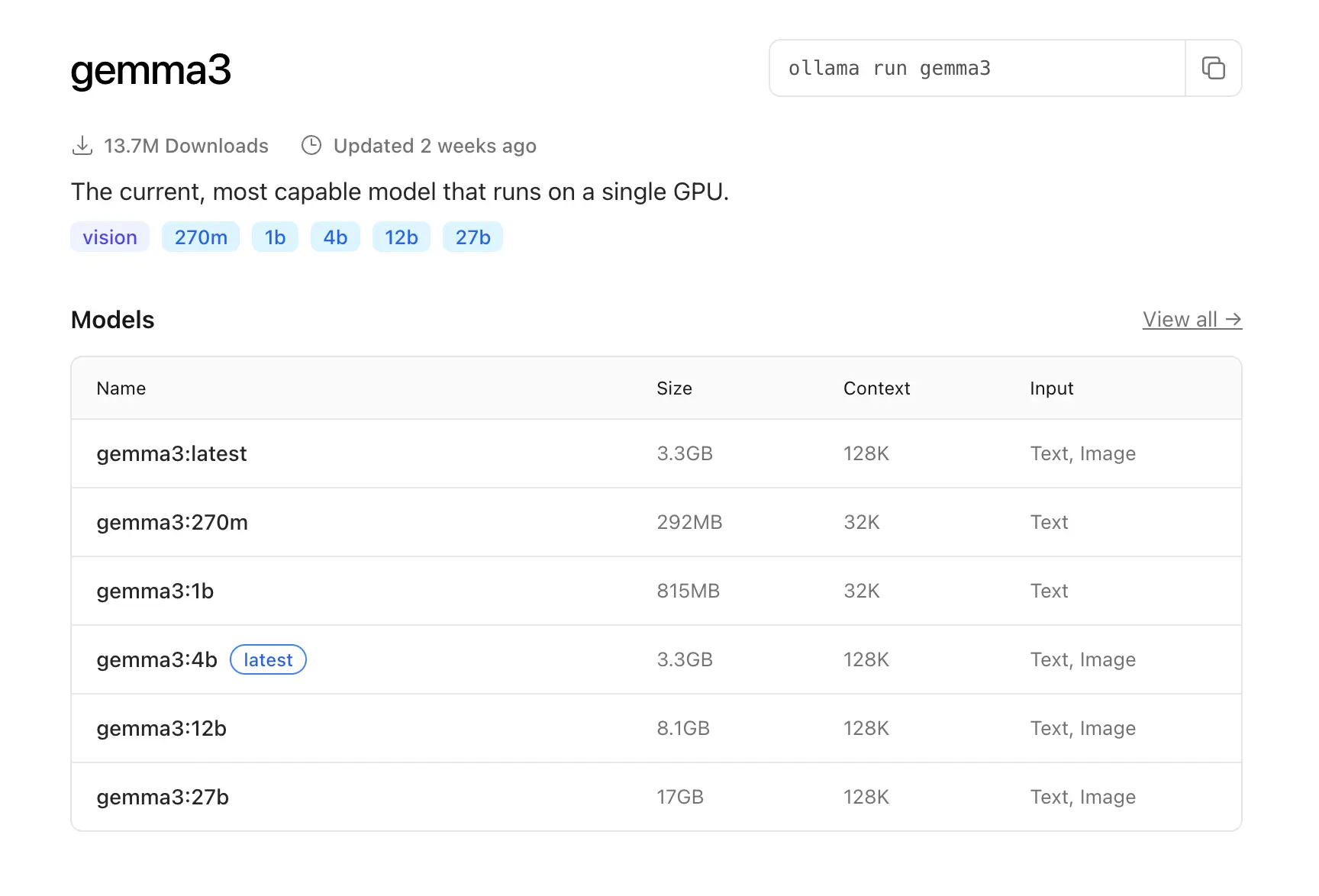
Aug 31, 2025 | source
we see that in Ollama you can choose several gemma3 models. The “size” and the numbers next to the name (e.g., gemma3:1b, gemma3:4b) refer to the number of parameters the model was trained with—roughly, the bigger, the more capable. Then look at Context: that’s the window you have available for CAG.
More simply, in the image below we pass a PDF that includes words and images, which are represented as tokens. If the PDF does not exceed the token limit, the model can rely on the PDF’s information; but as we keep “talking” to the AI about the PDF, it will gradually forget the oldest parts of the PDF content.
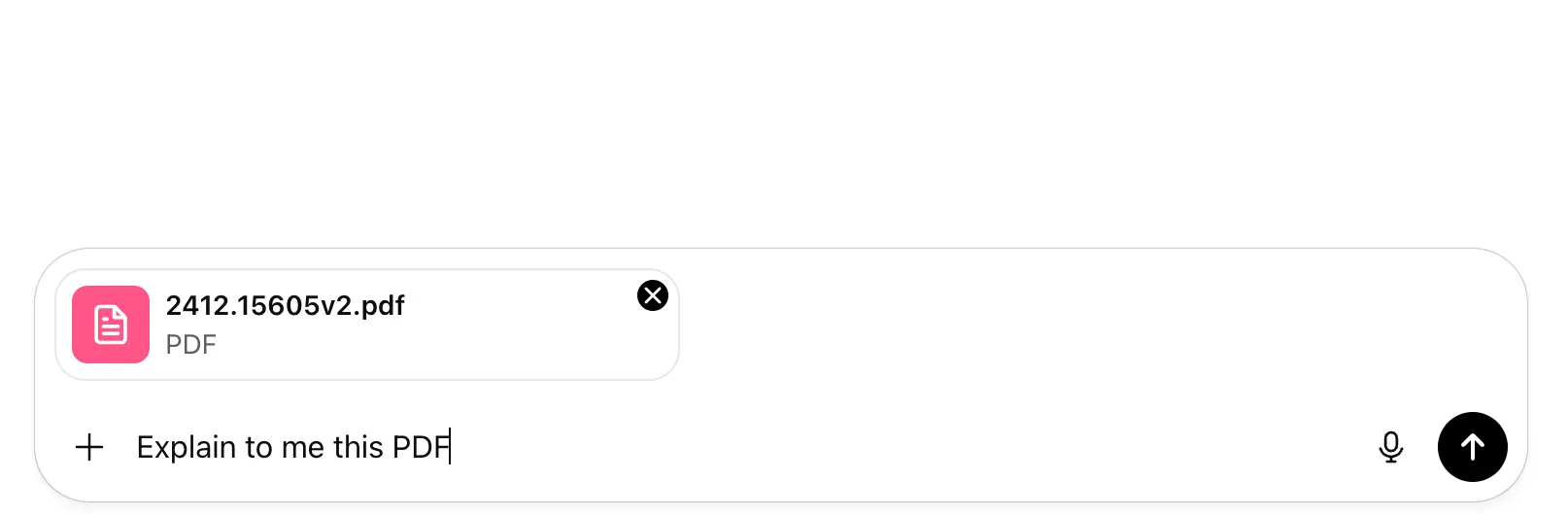
Aug 31, 2025 | source
I like to think of CAG as the quick way to consume specific information from a single data source—a document, a webpage, a court ruling. It’s not ideal for a company with hundreds or thousands of evolving documents and large volumes of information and processes that users consult frequently.
For that, RAG is the better fit.
RAG (Retrieval-Augmented Generation)
Think of the AI as a very smart student, but one who doesn’t know your manuals, contracts, or internal docs by heart. With CAG, some documents or information may fit, but if you have dozens, hundreds, or thousands of multi-page documents for your company processes, not everything will fit in context.
With RAG, you give the AI access to a private library of documents. Every time you ask a question, the AI retrieves the relevant information from that library and then generates the answer.
This way, you don’t modify the base AI; it connects to your data each time it answers. It’s also ideal if information changes often because you don’t rely on “remembering” it.
Example: an assistant that answers questions about your product catalog without training a model from scratch.
How do you implement RAG in a local/on-prem AI?
This is more involved. Unlike CAG—where picking a model with a huge context gets you most of the way (though it “forgets” older context as you go)—RAG avoids that forgetting.
In RAG, when you ask, for example: “What’s the name and phone number of the sales director at company X?” (imagine you’re part of a group of companies), your query goes through an encoder—think of a funnel—that converts the user question into numerical vectors so it can be matched in a vector database and identify what information the user needs, returning the specific data they’re asking for.
Of course, beforehand you must have processed your data. Information about the group of companies, employees, and directors with their phone numbers must be encoded and stored in the vector database.
The second step is that the same encoder queries the vector database for the most relevant pieces.
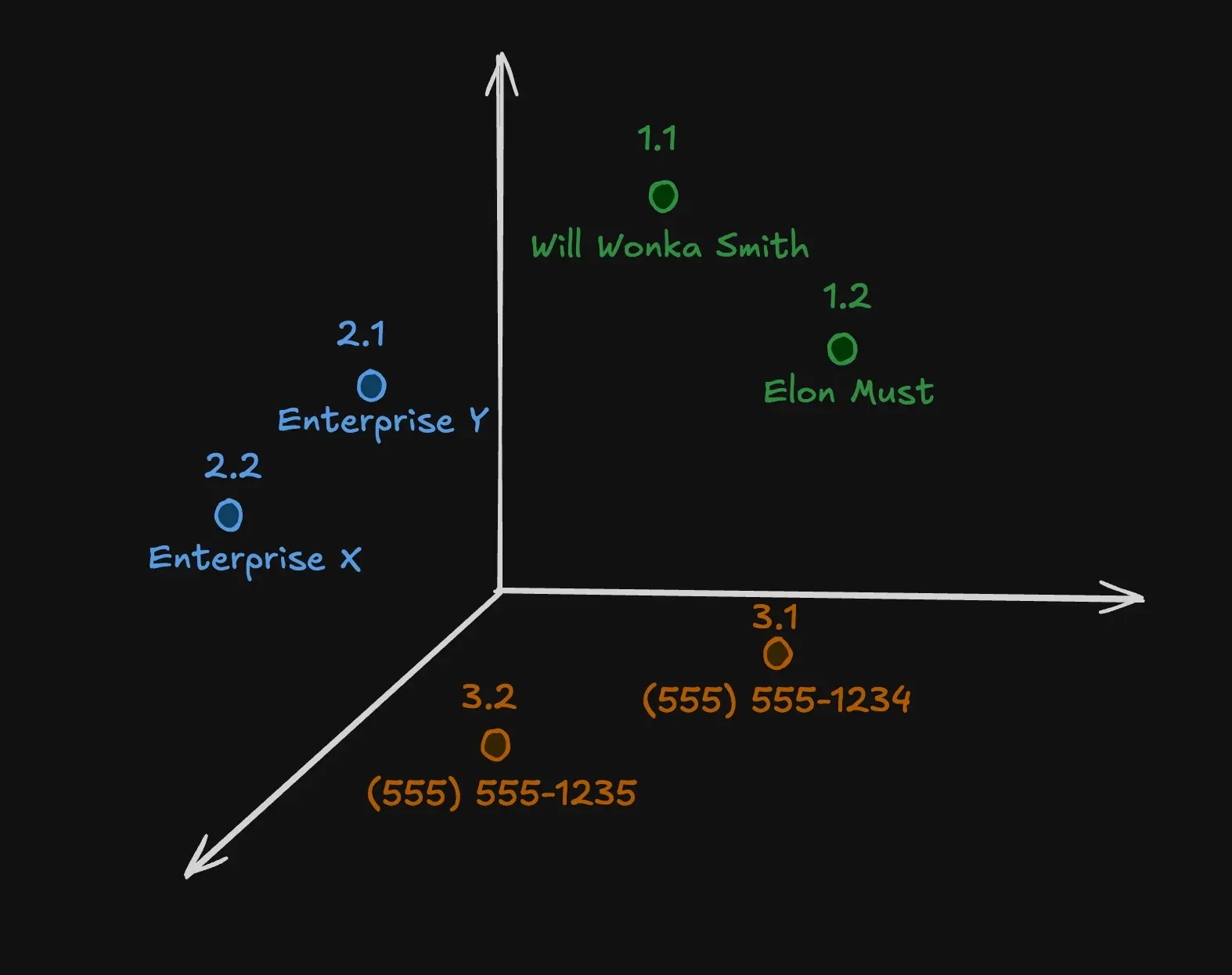
Aug 31, 2025 | own source
In the vector DB illustration, we see names, companies, and phone numbers. These have relationships: it will look for the sales director’s name and phone number. It could return something like:
“Name: Elon Must, Company: Enterprise X, Phone: (555) 555-1234.”
and pass that to the generative AI to craft the final answer.
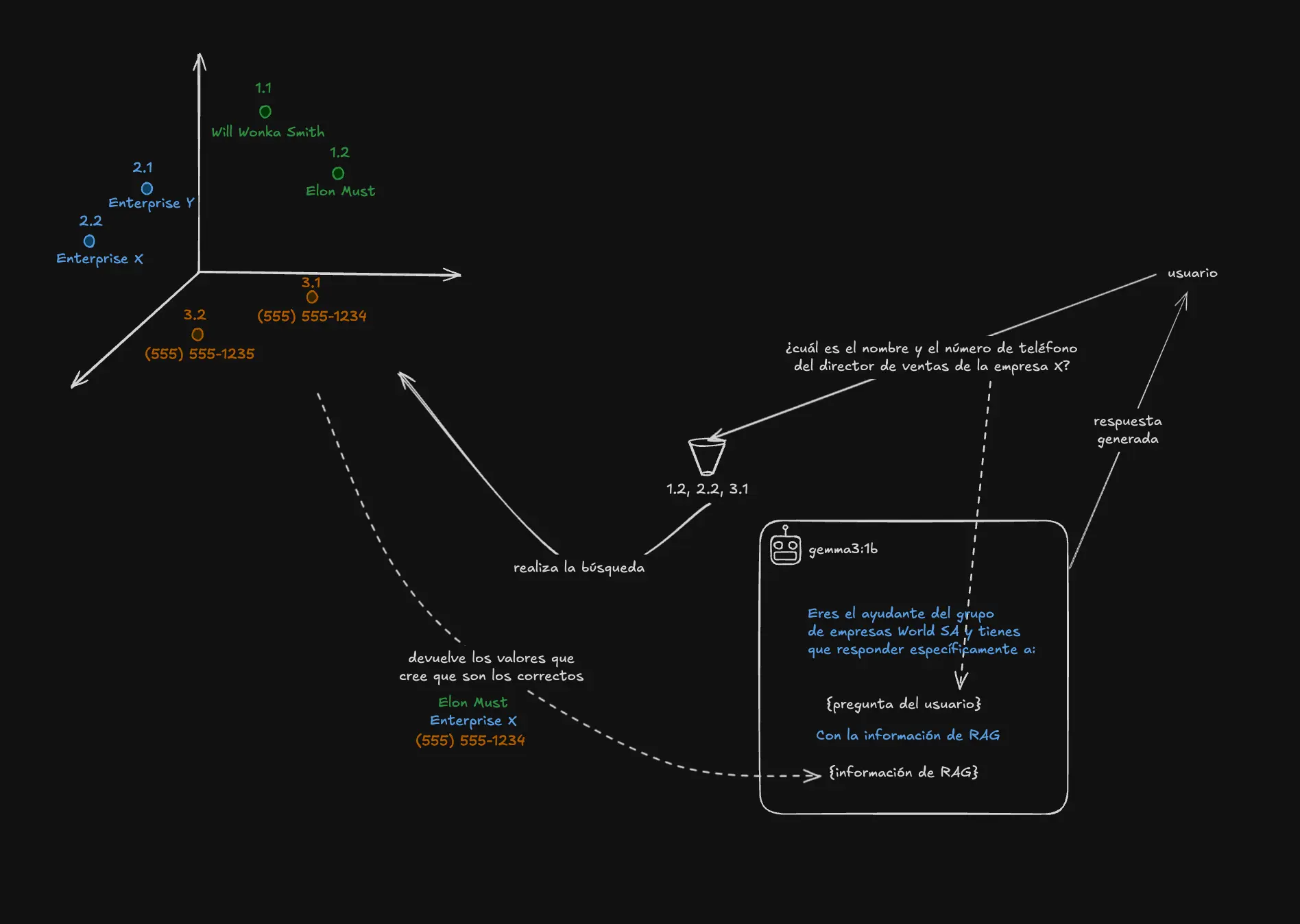
Aug 31, 2025 | own source
In the diagram above, we pass the generative AI some instructions (how it should behave/answer), plus the user’s original question, plus the information retrieved from the vector database.
A RAG system can become complex depending on the amount of data and relationships. The image below is an example representation of a vector dataset where each point is an article and its color represents its topic in a hierarchical topic model.

Aug 31, 2025 | source
Fine-tuning
Here we go a step further: Fine-tuning means TRAINING the AI model with your own examples so it “learns” to answer the way you want. It doesn’t just consult your data; it adapts to your style, vocabulary, and way of working.
This process is more complex. To pull it off, the first thing we need is lots of company data, in the form of question–answer examples, to train the model on our own data.
The steps would be:
-
Collect data
- You need many real company Q&A examples.
- The more and the better organized, the more the model will learn.
- Example: “How do I create an invoice?” → “Open the ERP, Finance menu, Invoices, click Create.”
-
Prepare the dataset
- Data must be in a format the model understands (JSON, CSV, or structured text).
- Usually split into prompt → answer pairs.
- Deduplicate and fix errors.
-
Choose a base model
- It can be an open model (e.g., LLaMA, Mistral, Falcon) or a private one.
- The key is that it supports fine-tuning.
-
Train (fine-tuning)
- Feed your data to the model in a training process.
- The model adjusts its internal “weights” to mimic your way of answering.
- Requires compute (GPUs/TPUs).
-
Validate and test
- Ask new questions (unseen during training) to check quality.
- If it fails, add more examples and iterate.
-
Deploy the model
- Save the fine-tuned model and use it in your system (intranet, app, chatbot).
- From then on, every answer follows your company’s style and knowledge.
Conclusion
Each approach has advantages. The key is choosing what best fits your goals—always with the peace of mind that you can do it privately and securely within your own infrastructure. Rolling out a private AI model for a company is worth considering, as it can deliver a very fast productivity boost.
For any questions about this, here’s my email: stemitomy@gmail.com.